Java Script und DOM
Ein wichter Teil der in der Webentwicklung im zusammenhang mit Java Script kaum mehr weg zu denken ist, ist DOM das Document Objekt Modell darauf möchte ich jetzt etwas näher eingehen. DOM ermöglicht uns den direkten zugriff auf Elemente oder Attribute eines HTML-dokuments. Ebenso erlabt es uns mit hilfe von Java Script das HTML dokument dynamisch Zu verändern. Dafür wird das HTML-Dokument in einen Dokumentenbaum gegliedert:
 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"><html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>HTML Seite</title>
</head>
<body>
<img src="../res_eigene/googlemaps.png">
<p align="center">Ein text Tag mit dem Attribut center</p>
</body>
</html>
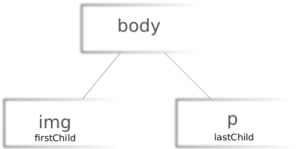
Anahnd dieses Beispiels kann man erkännen dass der Dokumentbaum eigentlich nur aus einer Rekursiven Auflistung der HTML-Tags Besteht. Diese Tags können in der "Punktschreibweise" ausgewertet werden. Also benutzen wir erstmal diesen Befehl:
document.body.firstChild
Wobei bodyden Wurzelknoten darstellt und firstChild den Ersten "kindknoten".
Also in diesem Fall würde hier der image-Tag ausgewertet. Wollen wir den letzten Kindknoten aufrufen wählen wir den Befehl:
document.body.lastChild
Demnach wählen wir hier mit den p-Tag aus. Eine weitere Möglichkeit ist es ein Array über childNodes[]
zu erzeugen so kann man dann auf die Kindknoten des Dokumentenbaums, b.z.w eines Elements über ein Array zugreifen. Zu beachten sei dass ein
Array immer bei "0" beginnt! Wollen wir nun innerhalb einer "Elementebene" auf einen kindknoten zugreifen müssen wir next
oder previousSilbling benutzen. Nun was können wir damit anfangen? Dazu sind die sog. "Node Eigenschaften" zu benutzen dies sind weitere
Glieder der oben genannten Notierung. Zunächst möchten wir den Typ des Knotens auswerten und ausgeben. Dazu benutzen wir die Funktion nodeType
hierzu ein kleines Beispiel:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>HTML Seite</title>
<script>
{
document.body.innerHTML = document.body.innerHTML.replace(/[\r \n | \s]/g,'');
alert(document.body.firstChild.nodeType);
}
</script>
</head>
<body>
<img id="bild" src="../res_eigene/googlemaps.png">
<p align="center" id="text">Ein text Tag mit dem Attribut center</p>
</body>
</html>
Anzeigen
Lasst euch an dem ersten Befehl nicht stören auch nicht an den Leerzeichen die bei der Darstellung fehlen. Dies hat seinen Grund denn Gecko Browser wie z.b Mozilla Firefox interpretieren
jede leerzeile als ein eigenes Text element. Die Funktion ist nicht elegant und auch nicht ressourcenschonend aber der
einfachheit halber hab ich sie hier angewendet.
Wenn ihr euch nun die Ausgabe des "alerts" anschaut bemerkt ihr, dass dort nur eine Nummer Ausgegeben wird dies entspricht einem Index, hier ein ausschnitt des Index:
1 => Elemet_node
3 => Text_node
2 => Attribut_node
Also erweitern wir die Funtion einfach um eine Switch Anweisung dann bekommen wir diese Ausgabe
Beispiel 1a Anzeigen
Um die ressourcen fressende Funktion oben zu umgehen verwenden wir nun
anstatt der firstChild, lastChild, Eigenschaften nun die Methoden getElementById(), getElementsByName(), getElementsByTagName()
Mit diesen Methoden kann mann nun die Tags direkt auswerten. Dabei bleibt der Syntax immer der Selbe.
document.getElementsById("tagid")
document.getElementsByName('nameAttribut')
document.getElementsByTagName("TagName")
Da dies Methoden des document-Objekts steht dies auch immer vor der Methode. In verbindung mit diesen Methoden kann man nun bequem weitere Informationen Auswerten
nodeName:
Gibt bei Element knoten den Tag namen zurück
nodeValue:
Praktisch bei Text_nodes, dort gibt das den Text aus.Beispiel 1b
Attribute
Genug von Elementen lasst uns einmal das Auswerten von Attributen und ihren Eigenschaften betrachten. Gemacht wird das über die
Eigenschaft attributes.Attributes ist einmal mit dem Index des Arrays oder mit dem Attributnamen aufrufbar. Ein Beispiel:
window.onload = function()
{
alert(document.getElementById("bild").attributes["src"].nodeValue);
}
Beispiel Aufrufen
Hier werten wir die URL des img Tags aus.
Zu guter letzt noch ein paar wichtige Methoden bei der verwendung von DOM.
appendChild("newNode") -- fügt einen Knoten an dass Ende eines anderen Knotens an.
removeChild() -- entfernt ein Element aus dem Dokumentenbaum
replaceChild("newNode","oldNode") -- ersetzt ein Element aus dem Dokumentenbaum
removeAttribute("attribut") -- Löscht ein Attributknoten aus einem Elment.
setAttribute("attribute","wert") -- Erzeugt ein neues Attribut mit dem gegebenen Wert